La 4e édition de la Botconf s’est tenue en plein coeur de Lyon, du mardi 29 novembre au vendredi 2 décembre dernier.
L’université Lyon 2 accueillait pour cette occasion les participants, venus des quatre coins du monde.
Cet article ne présente que quelques-unes des conférences que nous avons particulièrement appréciées. Les autres résumés seront disponibles au sein du prochain numéro de notre ActuSécu.
La Botconf 2016, en chiffre, cela donne quelque chose comme cela :
- 4 workshops
- 48 propositions de présentation
- 25 présentations (pour 40 auteurs)
- 10 Lightning Talks
- 12 sponsors
- 325 participants
- et tout cela, rondement géré par une équipe de 9 bénévoles seulement.
Avant de rentrer dans le vif du sujet, nous tenions donc à remercier cette équipe, qui a su, en quelques années seulement, faire de la Botconf un événement n’ayant rien à envier des autres conférences « sécurité » d’envergure internationale. Encore merci à Éric, et son équipe FredLB, Frédéric, Paul, Reza, Saâd, Vincent, Galadrim et Sebdraven d’avoir oeuvré au succès de cette dernière édition.
Advanced Incident Detection and Threat Hunting using Sysmon (and Splunk), par Tom Ueltschi
SYNOPSIS / SLIDES
Tom a partagé avec l’assemblée son retour d’expérience sur la mise en place d’un outil de monitoring des endpoints constituant son système d’information. La problématique peut être décomposée en plusieurs niveaux, allant de la sélection des sources d’informations, à la mise en place de l’infrastructure de collecte, sans oublier bien sur sa configuration. La quantité de traces générées peut en effet rapidement devenir problématique si la configuration adoptée n’est pas adaptée à l’objectif.
La solution retenue par Tom s’appuie sur Sysmon et Splunk, et avait été présentée à l’occasion de la conférence RSA 2016.
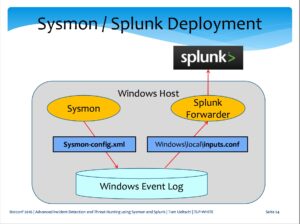
- Sysmon est un outil (disponible gratuitement) issu de la suite SysInternals, proposé par Mark Russinovich et Thomas Garnier. Ce composant additionnel peut être installé sur les postes Windows, afin de générer des traces au format Windows Event Logs, dès lors que certains « évènements » surviennent au niveau du système d’exploitation.
- Splunk est quant à lui utilisé au niveau des endpoints en mode « forwarder » afin de transférer les traces générées vers un collecteur central.
La configuration de ces deux composants est essentielle. Les règles utilisées pour effectuer les recherches faisant appel à un nombre important de paramètres système très variés (réseau, process, registre, DNS, etc.), une configuration trop restreinte pourrait limiter la capacité d’analyse et d’identification des postes infectés au niveau du système d’information. Inversement, une configuration trop riche pourrait avoir un impact en termes de volume de données transitant sur le réseau (bande passante plus ou moins limitée), collectées et stockées dans le collecteur central. Ce dernier paramètre n’étant pas des moindres, Splunk facturant à la quantité de données devant être analysée.
Plusieurs sources d’information peuvent être utilisées afin de définir ces règles. Le ThreatHunting Project est l’une d’entre elles. De manière générale, la conception de ces règles s’appuie sur des recherches d’informations disponibles en OSINT; recherches réalisées manuellement. Tom a ainsi cité les rapports d’analyse VirusTotal, les posters proposés par le SANS, les journaux du SANS ISC Diary, etc.
Un des points importants rappelés au cours de la présentation est le fait que le processus de chasse (hunting) est caractérisé par le fait de faire intervenir un humain, et qu’il ne peut donc pas être entièrement automatisé.
Tom capitalise ainsi depuis plusieurs années sur les informations récoltées, et dispose d’une base de connaissance de 180 règles distinctes, répartie selon les catégories suivantes :
- 21 FILE – file system
- 8 NET – network
- 20 PERS – persistence methods
- 52 PROC – process activity
- 4 REG – registry activity
- 21 SIG – sandbox signature
- 54 YARA – YARA rule matches (file, memory, pcap)
Detecting the Behavioral Relationships of Malware Connections, par Sebastián García
SYNOPSIS / SLIDES / VIDEO
Sebastián, universitaire argentin travaillant au sein de l’Université technique de Prague (CTU University), est venu présenter avec humour et dynamisme son travail sur les nouvelles méthodes d’identification de malware.
Bien que l’utilisation des IOCs soit de plus en plus industrialisée, il n’en reste pas moins que ces outils permettent de réagir seulement après identification d’un malware. Hors le processus de qualification restant bien souvent manuel, cette approche n’est pas pérenne. En effet, en termes de volumétrie, le nombre de malwares, aussi bien que le trafic réseau ne font qu’augmenter d’année en année. De plus, un certain nombre d’éléments techniques comme les payloads sont perdus (pas de DPI, ou de sauvegarde du trafic entrant, et malware de plus en plus souvent « file-less »).
Avec son équipe, Sebastián planche donc sur un projet d’automatisation de la détection des activités suspectes, en s’appuyant sur l’analyse des communications réseau au travers d’une solution de « Machine Learning ». L’un des principaux avantages de cette approche est donc la capacité de passer à l’échelle.
L’idée permettant d’appliquer du « Machine Learning » à ce problème d’identification consiste à modéliser les comportements observables au niveau des communications réseau. Le modèle proposé est le graphe constitué, pour chaque IP source, des éléments suivants :
- les noeuds correspondent aux tuples (DstIP, DstPort, Proto) ;
- les arrêtes correspondent aux séquences des flux d’un nœud à l’autre dans le réseau
Différentes caractéristiques peuvent ensuite être appliquées à ce graphe afin de le représenter visuellement :
- Plus une arrête est identifiée dans le graphe, plus celle-ci est épaisse.
- Plus un noeud est répété, plus il sera gros.
- Plus un noeud boucle sur lui même, plus il devient foncé.
Concrètement, ce modèle permet de modéliser un comportement normal et un comportement anormal de la manière suivante :


- le nombre de noeuds ;
- le nombre d’arrêtes ;
- le nombre de fois ou un noeud boucle sur lui même ;
- le nombre de fois ou une arrête se répète ;
- et enfin, le pourcentage d’arrête se répétant par rapport au nombre total d’arrête.
Ce dernier paramètre est particulièrement important dans leur étude. En effet, dans le cas de communications légitimes, ce pourcentage est extrêmement faible. Et au contraire, dans le cas des communications réalisées par un malware, ce pourcentage est extrêmement élevé. Il permet donc de différencier de manière fiable les communications légitimes des communications anormales. Un bot est donc trahi par ses comportements répétitifs.
Sebastián et son équipe ne se sont pas contentés de définir ce modèle théorique. Ce dernier a été appliqué au sein d’un projet Open-Source baptisé Stratosphere IPS. L’outil met concrètement en oeuvre le « Machine Learning » pour détecter les comportements anormaux.
À noter, l’ensemble des exemples de graphes présentés au cours de la conférence, et des jeux de données correspondants, est disponible librement sur le site du projet à l’adresse suivante :
Takedown client-server botnets the ISP-way, par Quảng Trần
SYNOPSIS / SLIDES / VIDEO
Quảng travaille pour un Fournisseur d’Accès à Internet vietnamien. La lutte contre les botnets est un sujet important pour un FAI, pour plusieurs raisons : pour protéger ses clients ainsi que son réseau, pour répondre à ses obligations légales (lorsque les Forces de l’Ordre lui font parvenir des requêtes officielles — « Law enforcement requests »), et enfin pour économiser la bande passante.
Après avoir présenté les problématiques couramment rencontrées dans la lutte contre les botnets (dépendance forte sur la bonne volonté des hébergeurs, aucune marge de manoeuvre avec les hébergeurs « bullet-proof »), il a présenté les avantages que peut tirer un FAI dans cette lutte, de par son positionnement au niveau du réseau.
Le FAI est en effet en capacité de monitorer et de contrôler le trafic transitant par son réseau, et en particulier au niveau du DNS. Un tel positionnement facilite également la surveillance des échanges, et si nécessaire la mise en place de solution de type DPI.
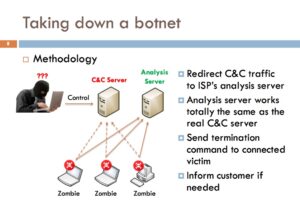
Globalement, la méthodologie proposée est la suivante :
- Rediriger le trafic à destination du serveur de commande et de contrôle (C&C) vers un serveur sous le contrôle du FAI, qui se comporte de la même manière que le serveur pirate.
- En fonction du botnet analysé, envoyer une commande spécifique pour désinstaller le malware sur le poste de la victime.
- Informer et sensibiliser la victime.
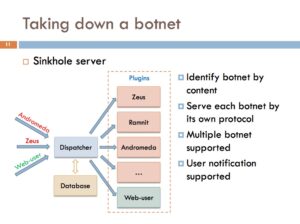
- Modification de l’entrée DNS sur le serveur DNS du FAI pour pointer vers le serveur d’analyse
- Modification des réponses/requêtes DNS (dans le cas où les utilisateurs n’utilisent pas le serveur DNS du FAI)
- Redirection directe du trafic IP, si la connexion s’effectue directement via une adresse IP.
Le chercheur a ensuite présenté les spécificités techniques du serveur C&C mis en place au sein du réseau du FAI. Pour être en mesure de demander aux bot de s’auto-désinstaler, il est nécessaire que le serveur soit capable d’identifier le « type » du bot, et de communiquer à l’aide du protocole de communication adéquat. Pour cela, un peu de reverse est nécessaire. Parmi les exemples de botnets actuellement supportés, Quảng a cité Ramnit et Andromeda.
Enfin, dernier point (et non des moindres), le type d’analyses réalisées et les méthodes employées (exécution de commande sur le poste de la victime pour la désinfecter) seraient complètement illégaux dans bon nombre de pays…
Function Identification and Recovery Signature Tool, par Angel Villegas
SYNOPSIS / SLIDES / VIDEO / GITHUB
Angel est venu présenter un outil développé au sein de l’équipe de Cisco Talos. Baptisé FIRST (Function Identification and Recovery Signature Tool), l’outil cible un public de Reverser et autre Malware Analyst, utilisant quotidiennement IDA Pro.
L’idée est de faire gagner du temps aux analystes en capitalisant sur le travail réalisé au cours des analyses passées, que ce soit sur des malwares de la même famille, ou sur des bibliothèques génériques (typiquement sur la partie Crypto, avec OpenSSL). L’outil permet donc de manipuler les métadonnées générées lors de l’analyse, de les sauvegarder sur un serveur ou de les charger depuis le serveur, et ainsi de les partager.
- OpenSSL
- 7zip
- aPLib
- ucl
- LibreSSL 2.3.1
- Mimikatz
- aPackage
- UPX
- ClamWin
- Alina Spark
- Dexter
- Grum
- Pony
- Zeus
- HackingTeam RCS
- …
A noter, l’ANSSI avait présenté lors de la dernière édition du SSTIC, un outil baptisé Polichombr permettant d’atteindre un objectif similaire.
Snoring Is Optional: The Metrics and Economics of Cyber Insurance for Malware Related Claims, par Wayne Crowder
SYNOPSIS / SLIDES / VIDEO
La présentation proposée par Wayne Crowder était particulière. En effet, Wayne n’est pas un « technicien ». Il travaille dans le monde des assurances, et est venu présenter son analyse de la situation en matière de gestion des risques « numériques » par les entreprises.
Son constat part du simple fait que le Cyber-crime coute de plus en plus cher aux entreprises, et qu’en termes de capitalisation, les sommes en jeux sont pharaoniques. Les professionnels du secteur estiment que les pertes pour les entreprises pourraient avoisiner près de 6 mille milliards de dollars d’ici à 2021. Cette problématique est donc l’objet de nombreuses attentions de la part des assurances, qui cherchent à répondre à cette problématique de différentes manières (couverture du risque pour leur client, mise à disposition d’équipe pour venir en aide aux victimes, sensibilisation des intervenants, etc.).

Ainsi, dans le monde de la construction, les assurances ont poussé des normes en matière de lutte contre les incendies. Dans le monde de l’automobile, les assurances ont poussé l’adoption des ceintures de sécurité, et de l’utilisation des vitres en verre de sécurité. Il en a été de même de dans le monde de la santé et de la médecine, et il en sera également de même dans le monde Cyber.
Actuellement, certains risques encourus par les entreprises sont déjà couverts par des polices d’assurance, comme :
- le vol d’informations (données personnelles, données bancaires, propriété intellectuelle) ;
- les malwares ;
- les attaques de DDoS ;
- l’arrêt temporaire d’activité métier ;
- les attaques de type Phishing ;
- ou encore les extorsions (arnaques au président et autres rançons).
Il est également revenu sur le concept de « bonne couverture par son assurance ». Ce qui convient à une entreprise ne conviendra pas à une autre, entre autres, car la législation n’est pas forcément la même dans tous les secteurs d’activité et dans tous les pays. Par exemple, même si les États-Unis ont déjà adopté une législation imposant la notification des attaques, l’Europe est en retard sur le sujet. Le GDPR, le projet de loi européen en matière de notification ne devrait ainsi rentrer en vigueur en Europe qu’en 2018. Autre exemple, même si la problématique de l’exposition au risque Cyber est de plus en plus souvent prise en compte par les grandes entreprises, cette dernière est complètement ignorée des petites et moyennes entreprises.
La présentation a également été l’occasion de revenir sur un grand nombre de cas médiatisé d’attaques, et de réponses apportées par les assurances à leur client (Sony, Tesco Bank, ICS, …).
En conclusion, même si les chiffres présentés concernaient tout particulièrement le marché américain, la tendance montre que la problématique reste la même en Europe, et que les mêmes constats pourront être faits d’ici à quelques années. En conséquence, les assurances vont développer peu à peu leur prestation en matière de réduction du risque Cyber, pour venir complémenter les apports de la sécurité opérationnelle. Ce mouvement a d’ailleurs déjà commencé, au travers des nouvelles polices d’assurance proposées, mais également au niveau de la structuration du marché. Ainsi, Symantec a procédé à l’acquisition de la société LifeLock, spécialisée dans le vol d’identité au mois de novembre dernier.

Pour clore cette édition, les organisateurs ont annoncé les principales informations sur la tenue de la 5e édition de la Botconf. L’évènement se déroulera du 5 au 8 décembre 2017, à Montpellier, dans le sud de la France. Suite au succès des Workshops lancé cette année, ces derniers seront reconduits l’an prochain.
Nous attendons avec impatience la prochaine édition de cette conférence de qualité. En attendant, rendez-vous dans le prochain numéro de l’ActuSécu pour un résumé complet et détaillé de cette dernière !
D’ici là, vous pouvez toujours aller voir les autres retours proposés par les autres participants à la conférence :
- NoLimitSecu
- Xavier Mertens (@xme)
- n0secure
- https://www.n0secure.org/2016/11/botconf-2016-j1.html
- https://www.n0secure.org/2016/12/botconf-2016-j2.html
- https://www.n0secure.org/2016/12/botconf-2016-j3.html
- Intrinsec


