
Ce mois de Mars 2024 a eu lieu le WestDataFestival à Laval. Une convention organisée par Laval Mayenne Technopole, avec pour objectifs la présentation et la démocratisation de nouvelles technologies et produits data pour les PME et collectivités locales de la région.
Un évènement pensé avec un haut niveau de vulgarisation permettant d’aborder tout un écosystème d’outils IA de manière simple et abordable rendant cet évènement accessible à tous.
Les participants ont pu bénéficier de présentations et de retours d’expériences proposés par différents professionnels sur des cas d’usages de ces outils mais également en stratégies de gestion de données. Plusieurs thématiques ont été abordées, mettant en avant différents secteurs d’activités comme la santé, la mobilité et les transports, le marketing mais également la cybersécurité.
La convention nous a permis de rentrer en contact autant avec des éditeurs de solutions IA que des utilisateurs de ces services. Plusieurs échanges intéressants autours des bonnes pratiques que doit adopter une équipe projet chargé de développer ce genre d’outils mais également divers écueils courants pouvant être évité. Des retours d’expériences que nous saluons et des conseils dont nous saurons nous inspirer pour le développement de nos services.
À travers cet article, nous vous proposons un rapide résumé des quelques conférences qui ont retenues l’attention de nos consultants.
Data et détection de Fraudes – Clémence Martinot, Jean-Yves Leguelinel
Clémence est Data Scientist au sein de Luminess, une entreprise spécialisée dans l’accompagnement à la digitalisation des process documentaires pour des grands comptes dans les secteurs de la santé, les services publics ou encore les banques et assurances. Clémence y développe des solutions IA facilitant la détection de faux-documents.
Jean-Yves est Adjudant de la Brigade de la gendarmerie de Mayenne et supervise des enquêtes impliquant des fraudes documentaires.
Jean-Yves nous rappelle que sur le territoire national, environ 6% des dossiers administratifs sont frauduleux, représentant un impact économique de 360 M€ par an pour ces administrations. La fraude documentaire concerne l’usage de faux-document dans des processus administratif, aussi bien des documents d’identité, des permis de conduire que des bulletins de salaires ou des factures. Les natures des fraudes sont diverses mais relèvent essentiellement des 3 grandes familles suivantes :
- La contrefaçon, correspondant à la création complète d’une copie d’un document officiel.
- La falsification, correspondant à l’édition partielle d’un document officiel.
- L’obtention indue, correspondant à la manipulation morale et intellectuelle d’un agent pour l’édition d’un document officiel.
Des exemples de documents à disposition de la gendarmerie nous ont été présentés, les participants ont pu convenir de la difficulté à discerner certains faux documents même pour certains professionnels dans l’assemblé.
C’est ici que rentre en jeu Clémence pour nous présenter ses travaux chez Luminess. Elle y développe un outil capable de détecter automatiquement en quelques secondes si un document est un faux ou non à partir d’un scan, une photo ou une courte vidéo. Une solution déjà intégrée par des clients grand compte, facilitant les process de création de dossiers administratifs aidant les opérateurs à valider ou non chaque demande.
Ici hors de question de laisser l’outil décider seul, les enjeux sont trop importants. L’interface associée permet de mettre en évidence pour l’opérateur chaque point d’attention relevé par l’algorithme de détection. Différentes mesures permettent d’offrir une explication et un niveau de confiance sur chaque défaut pouvant être une preuve de contrefaçon ou falsification. Cela offre un gain de temps majeur pour les administrations et un taux de faux-positifs très faible. L’algorithme est fiable avec un faible taux d’erreurs, mais permet surtout aux opérateurs d’être moins épuisés dans cette tâche d’identification qui demande une acuité visuelle et une concentration importante. L’outil leurs permet donc d’être plus alerte sur les détails qui ne serait pas déjà pris en charge par l’algorithme.
Évolution génétique pour l’IA frugale – Karol DESNOS
Les excellentes performances des algorithmes d’intelligence artificielle et notamment ceux de Deep Learning permettent aujourd’hui d’accomplir des tâches complexes avec une grande efficacité : génération de textes ou d’images ou encore assistance au développement informatique. Néanmoins ces modèles sont de plus en plus gros et nécessitent des ressources hardware toujours plus puissantes et rapides. Par exemple le modèle ChatGPT4 d’OpenAI est estimé être composé de plus d’un trillon de paramètres ! C’est en partant de ce constat que Karol DESNOS maître de conférences à l’INSA Rennes et chercheur à l’IETR nous présente une méthode à la fois efficace et frugale basée sur les Tangled Program Graphs (TPG) permettant de construire des IA de manière bien moins complexe que les techniques traditionnelles de Deep Learning.
Un TPG est un graphe orienté où les données d’entrées vont être traitées tout au long du graphe par des programmes. Ces programmes composent les arcs du graphe et sont en réalité des collections d’opérations mathématiques (addition, soustraction, exponentiel, …) dont la sortie est toujours un nombre. A chaque étape, c’est le programme ayant retourné la plus grande valeur qui est sélectionné et ainsi de suite jusqu’à atteindre une feuille du graphe qui va représenter les résultats du modèle.
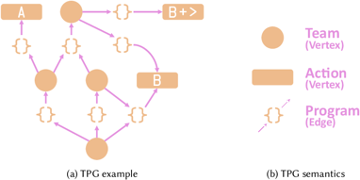
Architecture simplifiée d’un TPG
Desnos, Karol et al. “Gegelati: Lightweight Artificial Intelligence through Generic and Evolvable Tangled Program Graphs.” Workshop on Design and Architectures for Signal and Image Processing (14th edition) (2020)
Les TPG sont entrainés via une technique de Reinforcement Learning basée sur des algorithmes génétiques. Une cible d’entrainement à maximiser est définie (par exemple un score à atteindre dans le cas d’un jeu vidéo) et à chaque génération, des mutants sont générés en modifiants aléatoirement le graphe. Le mutant atteignant le score le plus haut est sélectionné et transmis à la génération suivante et ainsi de suite jusqu’à que les modifications n’apportent plus de changements significatifs.
Les avantages des TPGs sont multiples :
- Faible poids du modèle (moins de 100kB dans la plupart des cas)
- Rapidité d’entrainement et d’exécution
- Complexité de la solution en phase avec celle du problème
Par exemple, plusieurs applications des TPGs ont été présentées pendant cette conférence comme la reconnaissance de trame réseau ou encore l’identification d’appareil à partir de leurs défauts wifi.
Si vous souhaitez tester cette méthode d’apprentissage, l’auteur et son équipe ont développé l’outil open source gegelati (https://github.com/gegelati/gegelati) permettant d’implémenter des TPGs.
Création d’un Deep Fake en live – Pierre Cartier
Pierre Cartier, membre de l’association Le Mans School of AI, nous a fait la démonstration en live de la création d’un Deep Fake video. Le Deep Fake est une technique de synthèse multimédia visant à superposer plusieurs contenus distinct, audio et/ou vidéo, pour réaliser un nouveau contenu crédible correspondant à un mélange de ces différentes entrées.
Avec comme prérequis une courte vidéo d’une personne et un enregistrement audio de sa propre voix, Pierre est capable en quelques minutes et une cinquantaine de ligne de code de réaliser un Deep Fake. Pour l’exemple c’est la vidéo d’une interview filmée de Thomas Pesquet qui est détourné, parlant initialement de sa mission sur l’ISS, Thomas se retrouve reprendre les propos pré-enregistrés de Pierre et nous parler de la convention que nous sommes en train de suivre.
Avec seulement des outils open source déjà ancien (2020), les défauts sont facilement identifiables par le publique, notamment la tonalité de la voix qui n’est pas affinée aux transitions entre les phrases et la génération de la bouche pour la synchronisation labiale qui n’est pas parfaite, mais la preuve de concept est là.
Les techniques de Deep Fake étaient déjà connues de l’audience au travers d’usages malveillants, servant à certains acteurs pour diffuser des canulars ou désinformation, mais des usages aux bénéfices des entreprises sont possible. Des outils propriétaires avec des performances bien au-delà de cette démonstration existe déjà sur le marché. Ces logiciels trouvent leurs applications principalement dans le milieu de l’audiovisuel proposant des services de doublage automatisé, autant pour le cinéma que pour des petites entreprises ayant par exemple besoin de produire des vidéos de formation à rendre disponible en plusieurs langues.
Conclusion
Lors de ces interventions nous avons remarqués des questions récurrentes de la part des audiences. Une confusion générale et des interrogations sur les définitions que l’on donne au concept d’Intelligence Artificielle. Ainsi que des craintes sur les risques que représentent l’usage de ce genre d’outils.
Les solutions IA sont des outils numériques qui permettent d’automatiser certaines tâches au même titre que des solutions logicielles traditionnelles. La particularité est dans le fait que ces outils reposent sur l’analyse d’un grand nombre de données pour développer leurs services. Cela permet de déployer des heuristiques plus fines et souvent plus adaptatives et personnalisées que des logiciels traditionnels. En ce sens, les éditeurs de solutions IA préfèrent parler de leurs outils comme des Produits Data ou bien de solutions d’Intelligence Augmenté, pour conserver l’acronyme.
Le terme d’intelligence artificielle prête à confusion, laissant fantasmer le concept d’une copie d’intelligence humaine capable de s’adapter et porter une réflexion sur tous types de situations. Les produits data auxquels nous sommes confrontés ne sont pas encore à ce niveau de performances. Chaque outil est conçu pour répondre à une problématique bien précise et cherchent à atteindre un niveau d’excellence dans un champ de compétences défini par leurs éditeurs.
Au-delà des risques sociaux liés à l’automatisation et l’industrialisation de certaines tâches métiers, les risques associés à l’usage des produits data sont du même type que ceux connues pour des solutions logicielles traditionnelles. L’usage des données est encadré par les contrats de licence, rarement lues ni compris dans leurs intégralités par les particuliers qui manipulent ces outils, les pratiques de Shadow IT font courir un risque de confidentialité sur les données d’une entreprise. Des défauts d’implémentations ou de configuration peuvent également être présent, rendant possible des exploitations par différents acteurs malveillants. Il est toujours possible que la nature même d’un service soit utilisé de façon dévoyée à des fins initialement non prévues.
Les secteurs du numérique associés aux IA sont aujourd’hui en pleines effervescence, de nouveaux outils sont rendus disponible tous les jours. Tous les secteurs d’activités peuvent potentiellement bénéficier de l’intégration de ce genre d’outils. La démocratisation de ces outils est portée par des discours mettant en avant les bénéfices apportés par les IA, mais il est important d’accompagner ces discours par de la sensibilisation aux bonnes pratiques du numérique. Tous les utilisateurs ne sont pas formés aux différentes stratégies de gouvernance de données ou à la gestion des risques cyber. Chez XMCO, nous espérons pouvoir contribuer à cette sensibilisation. N’hésitez pas à nous faire part de vos interrogations en matière de risques cyber, nous sommes prêts à répondre à vos questions.
Antoine R. & Jeremy M.


