Cette année, XMCO participe à la conférence PassTheSalt, conférence française sur le thème de la sécurité informatique dont la particularité est que toutes les conférences se déroulent en anglais.
À cette occasion, lors de cette 6ème édition à Lille, XMCO vous propose un résumé de quelques conférences qui nous ont marqué parmi l’offre très qualitative que propose cet évènement.
Kerberos-NTLM
Présenté par : Clément Notin de chez TENABLE
Source du support de présentation : SUPPORT
Enregistrement vidéo de la conférence : VIDEO
Outils abordés :
- https://github.com/gentilkiwi/mimikatz
- https://github.com/dirkjanm/forest-trust-tools/blob/master/keytab.py
L’Active Directory repose sur divers protocoles parmi lesquels nous retrouvons LDAP, SMB ou bien RPC (« Remote Procedure Call »). Ce dernier est lui-même composé de divers types tel que MS-RPC qui repose sur le standard ouvert « DCE/RPC ». Au sein de l’outil Wireshark, lorsque ces échanges veulent être observés, il convient justement d’utiliser ce filtre « DCE/RPC ».
La problématique dans ce contexte est la capture des paquets concernés et plus particulièrement leur lecture. Les données étant chiffrées au sein des requêtes, cela empêche la détection de l’appel à certaines fonctions qui permettrait de déceler l’exploitation de certaines vulnérabilités au sein de l’environnement (ZeroLogon, PetitPotam).
Cependant, tout comme dans le contexte du protocole TLS, il est possible de déchiffrer les échanges réalisés via Kerberos ou NTLM au sein de Wireshark.
Kerberos
Pour répondre à ce besoin, l’auteur nous invite dans un premier temps à récupérer des clés de sessions utilisées pour le chiffrement au sein du protocole Kerberos. Diverses méthodes permettent cette récupération existes mais ce dernier les décrits comme étant en partie contraignantes. Celui-ci privilégiant une attaque nomme DCSync qui est selon lui bien plus efficace par la facilité et la rapidité d’exécution. En l’occurrence avec les droits d’un utilisateur privilégié (*Domain admin*).
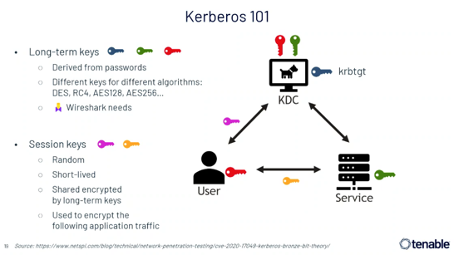
Une fois une clé ou plusieurs récupérées, il suffit de créer un fichier « keytab » à l’aide de divers outils tels que *kutils* ou du script *keytab.py* basé sur la suite *impacket*. Enfin, dans le menu des préférences au sein de l’outil Wireshark, il suffit de se rendre sur le sous-menu concernant les protocoles et plus particulièrement *KRB5* afin de sélectionner le fichier « keytab » précédemment créer.
Puis un nouvel onglet sera alors disponible au sein du « dissecteur » dans l’interface de Wireshark nous permettant d’observer les requêtes désormais déchiffrées.
NTLM
Cela fonctionne sensiblement de la même manière que pour le protocole NTLM à la différence qu’il faudra fournir le mot de passe dans le champ « NT password » dans le même sous-menu que précisé plus haut mais pour le protocole NTLM. Afin de bénéficier de la lecture des requêtes déchiffrées dans le nouvel onglet créé, il convient cependant d’utiliser la version v4.0.6 de Wireshark (ou v3.6.14 backport).
Il est également possible d’utiliser le hash NTLM directement à l’aide de nouveau d’un fichier « keytab » en précisant le type de clé.
PHP filter chains: How to use it
Présenté par : Rémi Matasse (Remsio) de chez SYNAKTIV
Source du support de présentation : SUPPORT
Enregistrement vidéo de la conférence : VIDEO
Cette attaque se présente dans un contexte d’une vulnérabilité d’inclusion de fichier local (LFI). Historiquement, cette vulnérabilité permettait de réaliser par extension des exécutions de commandes arbitraires sur le système (RCE), d’accéder à des informations sensibles (Information leak), de remonter dans l’arborescence du système pour atteindre des fichiers théoriquement inaccessible (Path traversal) ou encore de provoquer des dénis de service (DoS). Et bien d’autres vulnérabilités qui ont été en partie corrigées au cours des évolutions des précédentes versions de PHP.
Ce langage de programmation propose une forme d’outillage permettant de réaliser des actions sur les chaines de caractères, les fichiers ou autres objets appelé « PHP filters ».
Rémi Matasse nous présente alors diverses techniques à l’aide du chainage de ces filtres permettant d’exploiter de nouveau dans ce contexte des exécutions arbitraires de commande ou une lecture des fichiers à l’aveugle (blind leak file via Blind Oracle) sur le système.
Sans entrer dans le détail exhaustif des comportements de PHP observés favorisant la réalisation de cette attaque, ceux-ci reposent majoritairement sur les résultantes de l’encodage des caractères permettant de créer de la donnée ou de déceler la présence de caractère au sein des fichiers observés.
Certaines limitations sont cependant présentes dans un contexte réaliste :
- la limitation du nombre de caractères dans l’URL provoquant des erreurs HTTP 414 au-delà. Ceci apparaît contraignant lorsque le chainage de ces filtres dépasse 135 caractères dans les paramètres d’une requête HTTP GET
- L’usage de certaines fonctions empêche l’exploitation de cette vulnérabilité comme stats(),is_file(), file_exists(), etc.
- L’exploitation basée sur les erreurs peut prendre plusieurs heures pour récupérer les informations dans des fichiers volumineux
Cependant, un certain nombre de fonctions restent vulnérables parmi lesquels une partie sont présentées lors de la conférence :
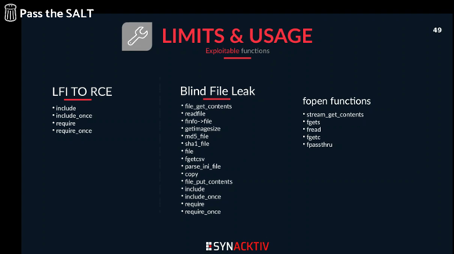
Outre cette difficulté d’exploitation dans un contexte réaliste, ce qui reste « intéressant » c’est qu’il n’y a pas de besoin d’avoir des droits en écriture ou de téléchargement de fichier sur le serveur pour pouvoir les exécute

Les cas d’usages seraient limités mais le terrain de jeu de la découverte de nouvelles exploitations dans ce contexte reste visiblement très vaste.
Afin de faciliter les tests d’exploitation, un outil est disponible sur le Github de SYNAKTIV : https://github.com/synacktiv/php_filter_chain_generator
Introduction to Sigstore: Cryptographic signatures made easier
Présenté par : Maya Costantini de Red Hat
Source du support de présentation: SUPPORT
Enregistrement vidéo de la conférence : VIDEO
De nombreuses attaques visant la chaine d’approvisionnement ont vu le jour ces dernières années, ciblant par exemple les logiciels tiers ou bibliothèques publiques. Pour se prémunir contre ce type d’attaques, les développeurs ont besoin d’attester l’intégrité et la provenance de leurs dépendances logicielles.
L’autrice de cette conférence nous présente ainsi une solution développée en partie au sein de Red hat visant à résoudre la problématique de signature et de vérification des artefacts logiciels (paquets de logiciels, image de conteneur, etc.).
Les outils existants, en particulier OpenPGP/GPG permettent d’arriver à cette fin, mais présentent des inconvénients tels que la gestion du stockage des clés privées et la rotation de celles-ci lors de leur expiration.
Ainsi, la solution proposée par Maya, SigStore, vise à résoudre d’une part les problématiques de signature et de vérification des artefacts logiciels, mais aussi de rendre l’intégration de cette solution plus simple pour les utilisateurs finaux, à la fois pour la signature des artefacts, mais également pour la vérification de ces signatures. En effet, SigStore propose:
- De n’avoir besoin d’aucune connaissance de la cryptographie ou des protocoles;
- Une interface simple pour rendre la signature accessible à tous;
- Pas de gestion et de rotation des clés privées;
- Un audit et une révocation plus facile en cas de compromission;
- L’utilisation de signatures liées à une identité publique et non à une clé publique.
Les utilisateurs peuvent donc générer des paires de clés éphémères et signer un artefact à l’aide d’un fournisseur d’identité tels que GitHub, Microsoft ou Google, qui seront utilisés pour générer la signature de l’artefact loogiciel.
Le projet SigStore prend exemple sur le projet Let’s Encrypt. En effet, lors de la signature d’un artefact, cet événement est enregistré au sein d’une base publique permettant la vérification de la signature de l’artefact.
Gepetto: AI-powered reverse-engineering
Présenté par: Ivan Kwiatkowski
Source du support de présentation: SUPPORT
Enregistrement vidéo de la conférence : VIDEO
Les récentes évolutions en matière d’intelligence artificielle et en particulier leur démocratisation ont permis de mettre en avant les facultés de ces modèles à traiter du code source, qu’il soit lisible et compréhensible par un humain ou non.
Ainsi, afin de vérifier cela, l’auteur a pris comme exemple une implémentation de l’algorithme RC4. Il a ensuite compilé ce code et l’a décompilé avec IDA. Il a ensuite demandé au modèle de langage de déterminer ce que ce programme effectue.
Le modèle de langage a ainsi été en mesure de déterminer l’algorithme RC4 mais également de déterminer à quoi les arguments de la ligne de commandes servaient.
Ivan a ensuite présenté une extension à l’outil de reverse enginerng IDA Pro en exploitant les fonctionnalités des modèles de langage de grande taille (LLM), et en particulier ChatGPT3.5 ou ChatGPT 4 d’OpenAI afin de faciliter les tâches de rétro-ingénierie.
Ainsi, cette extension propose deux fonctionnalités principales:
- la possibilité de demander au modèle de langage de réécrire le pseudo-code C décompilé en renommant les variables avec des noms cohérents avec le contexte de la fonction
- La possibilité de demander au modèle de langage d’expliquer ce que fait une fonction en écrivant un commentaire en en-tête de la fonction.
Cependant, l’auteur a présenté quelques limites à cet usage. En effet, les appels aux API de ces modèles de langage sont payants et représentent ainsi un cout de l’ordre de quelques Euros par session. D’autre part, les limites en termes de token qu’un modèle de langage peut traiter est un facteur limitant sur les fonctions pouvant être analysées par un tel outil.
Enfin, cela nécessite de partager le code décompilé avec un acteur externe.


